Lad mig sige det med det samme: Det her er ikke et vidundermiddel mod duplicate content, men det kan løse nogle af de problemer, som kan opstå i diverse CMS. Det er Google Webmaster Central, der bringer nyheden – i øvrigt samtidig med at Matt Cutts lancerede den på SMX West. Det handler om et nyt tag til headeren, og angiveligt vil Google respektere dette i langt de fleste tilfælde.
Det er nu 15 år siden, Google og de andre søgemaskiner introducerede Canonical URL Tag, og da der stadig her i 2026 er stor tvivl om, hvad det er, hvordan det virke rog ikke virker samt hvad der kan gå galt, har jeg opdateret dette indlæg med mere viden om Canonical URL Tag.
Canonical URL – det er det, det handler om
Vi snupper lige de sædvanlige kaffemaskiner. Du sælger dem på din hjemmeside, og en af modellerne er fra Saeco. Den vil du gerne vise under den varegruppe, der hedder “Saeco”, men du vil også gerne vise den under gruppen “kaffemaskiner til espresso” samt gruppen “italienske kaffemaskiner”.
Du har jo lært, at du skal have en masse god beskrivelse til dine produkter, så du har en god tekst til din Saeco kaffemaskine – lad os sige 200 ord. Din hjemmeside hedder svendbent-kaffemaskiner.dk – og du har altså den her kaffemaskine under tre varegrupper:
- svendbent-kaffemaskiner.dk/saeco/model12
- svendbent-kaffemaskiner.dk/espresso/model12
- svendbent-kaffemaskiner.dk/italienske/model12
Hvis du har læst med her på bloggen tidligere (og ikke tilhører majoriteten af ansatte i danske webbureauer…) vil du allerede nu se, at her er der et alvorligt duplicate content problem. Lad os sige, at din foretrukne side er svendbent-kaffemaskiner.dk/saeco/model12. Indtil nu har du ikke haft andre muligheder for at undgå duplicate content end at have tre helt forskellige tekster om model 12 i de tre varegrupper – eller spærre Googles adgang til de to af dem.
Nu kan du sætte et tag ind i headeren på de to (eller mange) sider, der er “kopier” af den originale – og dermed fortælle Google, hvilken af dem du foretrækker som den, de skal medtage i indeks og søgeresultaterne.
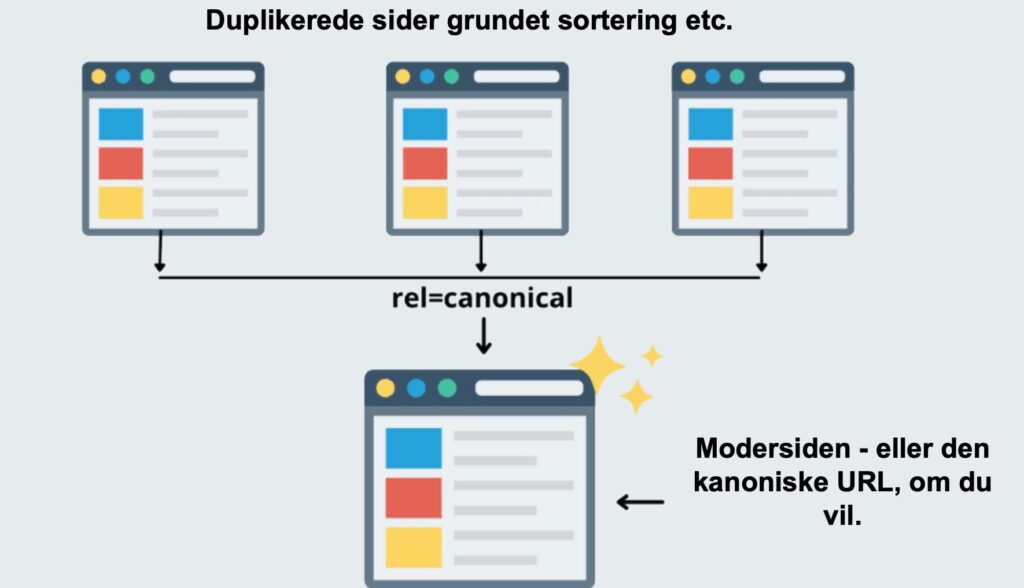
Sådan bruger du det nye “Link rel” tag
Hvis det er dig, der ejer svendbent-kaffemaskiner.dk, skal du indsætte tag’et her: <link rel=”canonical” href=”http://svendbent-kaffemaskiner.dk/saeco/model12″ /> i headeren på svendbent-kaffemaskiner.dk/espresso/model12 og svendbent-kaffemaskiner.dk/italienske/model12
Dermed fortæller du Google (og angiveligt også andre søgemaskiner), at det er svendbent-kaffemaskiner.dk/saeco/model12, der er moderen og den side, de skal prioritere.
Det er lidt smart, ikke?
Sorteringer efter pris, farver m.m.
Lad os sige, du har en side med kaffemaskiner – https://svendbent-kaffemaskiner.dk/espresso/. På den side har du en masse kaffemaskiner til espresso. Dit shopsystem gør det muligt at sortere visningen efter pris, popularitet og nyeste for eksempel.
Lad os sige, en gæst nu sorterer efter pris. Så kan den skabte URL se således ud for eksempel: https://svendbent-kaffemaskiner.dk/espresso/?sort=pris – og husk her på, at indholdet på den URL er det samme som på https://svendbent-kaffemaskiner.dk/espresso/ men blot i en anden rækkefølge! Altså duplicate content.
Med et korrekt indsat Canonical URL Tag på https://svendbent-kaffemaskiner.dk/espresso/?sort=pris, der ser således ud:
<link rel=”canonical” href=”https:svendbent-kaffemaskiner.dk/espresso/” /> vil Google og alle andre søgemaskiner forstå, at den kanoniske URL er https:svendbent-kaffemaskiner.dk/espresso/ og der vil ikke være tale om duplicate content.
Bonus her er, at et link fra en anden hjemmeside til https://svendbent-kaffemaskiner.dk/espresso/?sort=pris får al sin linkværdi overført til https://svendbent-kaffemaskiner.dk/espresso/
Læs mere hos Google eller hos Joost – eller tag den lange version hos Rand fra SEOmoz
Hvad er et Canonical URL Tag?
Et canonical URL tag er et HTML-element, der bruges til at angive den foretrukne version af en web-side, når der findes flere kopier af samme indhold. Dette tag fortæller søgemaskiner som Google, hvilken version af siden der bør indekseres og vises i søgeresultaterne.
Sådan virker det
Canonical tagget indsættes i HTML-headeren på en webside. Når en søgemaskine crawler en side, vil den registrere dette tag og forstå, at den angivne URL er den ‘autoritative’ eller foretrukne version af indholdet. Dette er særligt nyttigt i tilfælde, hvor indhold duplikeres på tværs af forskellige URL’er på samme domæne.
Fordelene ved at bruge Canonical Tags
- Forbedrer SEO: Ved at undgå duplicate content, hjælper canonical tags med at forbedre en hjemmesides SEO-værdi.
- Forenkler indeksering: Det gør det lettere for søgemaskiner at forstå og indeksere hjemmesidens indhold korrekt.
-
Bevarer link equity: Det sikrer, at eksterne links, der peger på duplikerede sider, akkumuleres på den autoritative side.
Potentielle faldgruber og problemer
- Fejlagtig brug: Forkert anvendelse af canonical tags kan føre til, at søgemaskiner ignorerer vigtige sider.
- Kompleksitet i store websites: På store websites med mange sider kan det være udfordrende at administrere og holde styr på alle canonical tags.
Kort sagt
| Fordel | Ulempe |
|---|---|
| Forbedrer sideindeksering og SEO | Kræver nøjagtig og konsekvent brug |
| Hjælper med at undgå straf for duplicate content | Fejl kan føre til ignoreret indhold |
| Bevarer og centraliserer linkværdi | Kompleks håndtering på store websites |
Se videoen med Matt Cutts om Canonical URL Tag her:
Rosenstand out!

Det var da en god nyhed. En stor hjaelp til os der bruger tid paa at lave flere forskellige beskrivelser af samme produkt.Vi maa jo saa bare haabe at cms udbyderne er hurtig ude med en opdatering, saa det bliver nemt at haandtere.
Jo såmænd, Lars. Men det kræver jo, at de opdager, det er muligt, ikke?
Når og hvis cms udbyderne så opdager det, vil de fleste af dem jo nok blot tilbyde det som et ekstra modul.
Det er en rigtig god nyhed – og vigtigt at søgemaskinerne er gået sammen om at indføre det som standard. Det rejser dog stadig nogle spørgsmål som hvor mange efterfølgende canonical urls søgemaskinerne følger – og hvad der sker hvis flere sider med forskeligt indhold påråber sig retten til samme canonical url.
@Mikael: Det kræver jo blot, at man kan tilføje et tag til headeren på sideniveau. Men du har sikkert ret i nogle tilfælde.
@Rasmus: Sammenstød mellem flere forskellige sider der påberåber sig retten til samme canonical URL vil kun kunne opstå i praksis på samme domæne – og så er det jo en fejl begået af webmasteren. Den slags kan søgemaskinerne ikke tage højde for. Canonical URL tag’et fungerer ikke på tværs af domæner mig bekendt.
Spændende nyhed.
Har det ellers ikke været en udmærket løsning at bruge robots.txt til at blokere de andre sider med eller har den løsning nogle problemer som det nye tiltag udbedrer?
Jo – men i robots.txt kan du sætte “Disallow”, og så indekserer søgemaskinen ikke siden. Du får heller ikke værdi af indgående links til dine “duplikerede sider” – det gør du ved brugen af Canonical tag’et, så der er faktisk ingen sammenligning mellem de to metoder.
Med det nye tag fortæller du søgemaskinerne, at de bestemt gerne må crawle og indeksere siden – men at du foretrækker, at de ranker en anden side. Og at du gerne vil have linkjuice ført med over.
Okay, ja så er der jo en række fordele ved det nye tag. Og samtidigt er det jo nemmere at anvende end robots.txt – vil jeg tro. Men begge ting er nok rimelig avanceret hvis det skal gøres automatisk på en webshop med 1000+ produkter der krydses på flere forskellige måder…
Måske er jeg ved at fatte noget af det, og så alligevel.
Jeg har haft overvejelser omkring kopieret indhold, fordi jeg er ved at få lavet flere af mine sider som e-bog i pdf format. Her på bloggen har du tidligere fortalt om to andre løsninger til at undgå kopieret indhold. Egentlig var mine overvejelser endt. Jeg havde valgt løsningen med en seperat mappe, kombineret med en robot.txt.
Men nu dukker de op igen. Som jeg forsttår denne blogpost, og specielt din kommentar nr. 7. Så bør jeg glemme alt om en seperat mappe, og anvende denne løsning at hensyn til værdien af indgående link. Og så alligevel. Jeg har en fornemmelse, som måske er meget forkert, af at du ikke er helt så klar i mælet som du plejer at være. Når jeg læser lidt mellem linierme på denne post får jeg det indtryk, at da du skrev den sad du og tænkte på ord som muligvis og måske.
Så nu er jeg forvirret igen – igen.
Nu hvor der er tre løsninger, er det blevet væsentlig sværere, at vælge hvilken af løsningerne man skal vælge.
Kan der opstilles nogle retningslinier for i hvilke situationer, man bør anvende den ene løsning frem for de andre. Eller er det mere et spørgsmål om religion?
Endnu en funktion til administrationsdelen i vores butik. 😉
Nu har jeg godt nok endnu ikke styr på, hvor detaljeret Google er omkring duplicate content – altså om det kun er på sideniveau, eller om det også er helt ned til afsnitsniveau.
Jeg er f.eks. ved at lave en butik, hvor menuen indeholder varekategorier. En vare kan blive vist i flere kategorier, f.eks. den overvordnede “Tog” og den underordnede “Brio”. Men vil Google så opfatte teaseren som duplicate, når den vises sammen med 100 andre tog under “Tog” og sammen med 30 andre under “Brio”? Eller vil hver af disse oversigtssider blive opfattet som unikke?
Som jeg har forstået det indtil videre, er det nok at sikre, at hver produktside kun har én indgående linkdefinition, dvs. linket fra en oversigtsside (f.eks. Brio) skal hedde det samme som linket til den samme side, når der linkes til siden fra Relaterede produkter.
@Jan: Det kan godt være, du har lidt ret. Det er jo en HELT ny metode, og der er ikke rigtig nogen, der har data fra tests af det. Vi har kun, hvad Google siger. Ofte passer det jo også, hvad de siger. I dit tilfælde ville jeg ikke benytte den nye metode, for der er ingen, der har bekræftet, at tag’et virker i en PDF. Det kan godt være, det gør – men det kan også være, det ikke gør.
Generelt er det jo farligt at sige noget skråsikkert om en metode, der er helt ny. Men jeg vælger at tro på, at Google har styr på det – så der er ikke så meget måske over det, som du opfatter.
@Johnny: Teasere bliver som regel ikke omfattet af DC, hvis de er korte nok. Se f.eks. denne blogs forside – den indeholder jo uddrag af de seneste artikler, men der er ikke noget her, der ikke ranker super 😉
Det er en spændende nyhed, gad vide om de ændre ved “straffen” ved reelt DC…?
Hvorfor skulle de ændre håndteringen af duplicate content? Google kæmper jo ikke med problemet for at straffe webmastere men udelukkende for at levere så gode søgeresultater som muligt.
Umiddelbart en kanon (canon? :-P) smart feature, men jeg har en lille smule svært ved at se problemstillingen i praksis:
Hvis der er tale om at du har 3 sider med det samme indhold, f.eks. den samme kaffemaskine under 3 kategorier, er det så ikke næsten ligemeget at Google markerer 2 af dem duplicate, og dermed ikke tager dem med i sit indeks?
Det er jo den samme kaffemaskine, og siderne vil være praktisk taget ens på nær kategorinavnet.
Og hvis en webmaster er avanceret nok til at identificere dupe content problemer, og implementere den nye tag, så er han sikkert også avanceret nok til at undgå problemet ved at lave små ændringer i indholdet.
Hej Thomas
Jeg ved godt, at der ikke skal mere end et tag til, men når jeg tænker på, hvad mange cms udbydere laver af underlige moduler, som ofte kræver meget lidt programmeringsmæssigt, men som kan komme til at lyde af noget meget smart i kundernes ører, så vil det på ingen måde undre mig, om nogen af dem vil forsøge at sælge det som et modul. Jeg har netop oplevet, at en kunde hos et cms-firma skulle give mere end 50% af hjemmesideløsningens pris for at erhverve moduler, der gør, at han vil kunne lave seo. Det er efter min mening helt urimeligt.
Så min kommentar var blot en spydig joke til cms-udbyderne, men det er desværre nok de færreste af dem, der læser med her.
@Søren: Jamen…? OK – hvis man ikke kan undgå DC grundet f.eks. sit system, så er det da 100 gange bedre selv at have kontrollen frem for at overlade den til Google. Jeg forstår godt, hvad du mener, Søren, men fakta er jo stadig, at det er meget, meget få webbureauer (og endnu færre af deres kunder), der har styr på DC. I et større dynamisk system med autogenerering af diverse gruppesider vil det nye tag være nemmere at implementere end at sidde og omskrive tekster. Eller hva’?
@Mikael: Jo – jeg kan se i Analytics, at i hvert fald de 8-10 største udbydere i Danmark er flittige læsere her. Så de læser skam med 😉
Kan man se ip-numre og hostnames i Google Analytics? Eller er det et andet Analytics du omtaler?
Jeg kender kun ét Analytics – og ja: Det kan man da!
Nåh der… Selvfølgelig 🙂
@ diskussion om, hvordan google (o.a. søgemaskiner) vil håndtere multiple addressing:
Rosenstand, du skriver:
“Sammenstød mellem flere forskellige sider der påberåber sig retten til samme canonical URL vil kun kunne opstå i praksis på samme domæne – og så er det jo en fejl begået af webmasteren. Den slags kan søgemaskinerne ikke tage højde for.”
Det kan de vel i princip og praksis godt — selv om de ikke kan læs tanker, så skal dobbeltaddresseringen jo tackles på en eller anden facon.
Seomoz-artiklen, du linker til, nævner indholdsanalyse og algoritmiske nøgletal som værn mod menneskelige fejl — og manipulationsforsøg.
Go’ weekend til alle!
/Kasper
@Kasper: Ja – hvis du virkelig mener, at en relativt tilfældig udvælgelsesproces af én af mange URL’s med samme indhold er at håndtere duplicate content godt. Men jeg mener, at det er en skidt håndtering i rigtig mange tilfælde.
Tag f.eks. printvenlige sider der indekseres og rankes højere end den originale side. Det er håndteret af søgemaskinerne, og resultat er en side uden links og konverteringsmulighed. Igen: Ét er teori – et andet er praksis. Og også her gælder mit yndlingsudtryk – “Virkeligheden er klog”.
Der er jo en grund til, at søgemaskinerne har valgt at honorere det nye tag – og det er, at de ikke er i stand til at håndtere duplicate content i brugernes og webmasternes interesse. Og som du selv skriver: Det skal jo håndteres på en eller andet facon, og det gør de så nu.
Jeg kan ikke rigtig finde ud af, om du er uenig med mig (og Google, Yahoo og Live), eller om du bare ville fylde lidt på et fromt ønske om en god weekend? Lige over – uanset 🙂
Hehe — det fromme ønske om en god weekend var skam noget sekundært, men ikke desto mindre hjerteligt ment!
Til sage(r)n(e):
Jeg var en smule uenig med dig, da du skrev:
“@Rasmus: Sammenstød mellem flere forskellige sider der påberåber sig retten til samme canonical URL vil kun kunne opstå i praksis på samme domæne – og så er det jo en fejl begået af webmasteren. Den slags kan søgemaskinerne ikke tage højde for.”
For søgemaskinerne er jo nødt til at tage højde for, at folk ta’r fejl bevidst el. ubevidst fejl med deres forsøg udi at bruge canonical-tag’et. Og det gør de [søgemaskinerne] så vha. indholdsanalyse og algoritmiske nøgletal.
Når det er sagt, så giver tag’et mest mening for dem, der ved, at de har et duplicate content-problem. Og hvis de ved det, så burde de finde en bedre løsning.
For at svare på dit spørgsmål: “hvis du virkelig mener, at en relativt tilfældig udvælgelsesproces af én af mange URL’s med samme indhold er at håndtere duplicate content godt. Men jeg mener, at det er en skidt håndtering i rigtig mange tilfælde.”
Så er det naturligvis ikke noget jeg mener. Hvorfor satse på, at en søgemaskine kan læse og indeksere i mit favør, når jeg har muligheder (i form af en mere fornuftig arkitektur, frem for lappeløsninger som canonical-tagget) for selv at bestemme.
Kunne det tænkes, at du har fejllæst mit indlæg derhen, at jeg taler om dc generelt, og ikke canonical-tagget?
Jeg er sgu lidt pjattet med det jyske lige over! Så go’ weekend igen!
/Kasper
Ok, jeg tror, jeg har luret, hvad der gik galt — følgende sætning —
“hvordan google (o.a. søgemaskiner) vil håndtere multiple addressing”
er tvetydig. Jeg mente multiple addressning _med_ canonical-tagget — ikke duplicate content generelt.
Makes sense?
/Kasper
Ja – det giver lidt mere mening, må jeg sige.
I en ideel verden er der ikke brug for hverken Canonical Tag eller for ABS bremser. Men så længe verden ikke er ideel, vil programmører og andet godtfolk fejle og chauffører undlade at bremse korrekt. Og så er både Canonical Tag og ABS altså bedre end rå mængder duplicate content og krøllet metal. Jeg er jo pragmatiker 😉
Men det løser stadig ikke problemet for alle dem der handler med varer der i forvejen er præsenteret på nettet gør det. Deres sider vil jo forudsat de bare kopierer fra deres leverandør vel stadig rammes af duplicate content vil de ikke ???
jvf. dit indlæg https://www.concept-i.dk/blog/naar-duplicate-content-rammer.html
kommentar nr. 10
Bare så en NOOB som mig lige får det ind med skeer og forstår sammenhængen.
/kenneth
Hej Kenneth
Velkommen her! Nej – det problem løser du kun ved at skrive dine egne unikke tekster til dine produkter. Det gør du forhåbentlig allerede?
Og dernæst er du nødt til at sikre diog mod kriminelle konkurrenter, der vil stjæle dine tekster – her er http://www.copyscape.com en god vagthund.
Ikke endnu, da jeg ikke sidder med hænderne så dybt i suppen endnu, men det er meningen jeg efter mit jobskifte for 4 uger siden skal til at sidde og røre i suppen i den afdeling jeg er blevet flyttet til.
og jeg bliver mere og mere glad for det, og tiltrukket af denne forunderlige verden af SEO
/kenneth
p-lindberg.dk/Soegeside.aspx?ArticleID=60032
Har lavet en søgning på dette site, da jeg kan se det drivhus mange steder, hvordan tolker jeg så resultatet af søgningen ??
Opj.d har så den bedste ranking og så i en PDF eller hva ??
Og P-lindberg.dk kommer slet ikke med på første side…..
/eichmeier
hvordan tjekker man sine tekster iden man lægger dem online ?
Sig til hvis jeg stiller for mange spørgsmål eller skal stille dem andetsteds, eller skal læse mere om det.
Vil meget gerne have links hvor jeg kan læse mere og læse mere.
/kenneth
Sidder du ved P-lindberg.dk? Bare af nysgerrighed…
Jeg må indrømme, at jeg ikke forstår dine spørgsmål. Kan du ikke uddybe, hvad det er, du er i tvivl om?
Jeg har kørt en copyscape.com søgnig på den side jeg har lagt et link ind til, og så fået et resultat frem.
Der kan jeg så se hvad der er ens med den tekst på siden jeg søger på og de andre sider, og er det SKIDT uanset om det kun er 3 ord eller 5 ord ?? Den skal vel HELST komme med ingen resultat overhovedet.
Kan man tjekke sine tekster for copy INDEN man lægger dem op.
/kenneth
Nogle få ords sammenfald betyder ikke noget – det vil du jo aldrig kunne undgå. Hvis du bruger den betalte version af Copyscape, kan du selv indstille, hvor “kræsen” systemet skal være.
Hvorfor tjekke teksterne, inden du lægger dem op? Hvis du skriver teksterne selv, er der jo ingen ko på isen. Og når du skriver dem selv, er det blot bagefter, du skal tjekke for tyveri.
Og hvis du benytter standardtekster fra leverandøren, er der heller ingen grund til at tjekke dem først, for du er alligevel langt fra målet. Du skal ikke bruge standardtekster, hvis du vil noget seriøst med den pågældende webshop. Og så’n er det bare.
Der ER et stort stykke arbejde i at skabe en succes online. Det gælder også teksterne.
Ok, JA, der er et MEGET stort arbejde i den online succes nogen har og MANGE prøver at få, men det er for mig en helt ny og MEGET spændende verden og jeg er meget glad for mine nye opgaver og udfordringer mit job giver mig
/kenneth
Det lyder jo næsten for godt til at være sandt!
Det er virkelig en mulighed jeg har savnet. LÆNGE!!!!
Endnu engang beviser du at det er en rigtigt god forretning at holde et vågent øje med din blog.
Tak, Jeppe! Husk nu, at det foreløbig er i Beta. Men jeg har allerede nu fantastisk gode resultater med Canonical Tag’et på et et par test, jeg har kørt sammen med kunder. Hvis de resultater holder i en større skala, er det bare godt!
Jeg forsøger at bevare jordforbindelsen, men det er virkeligt noget jeg har savnet og som vil gøre mit liv en del lettere hvis det holder.
Super nyhed. Så er det alligevel ikke kun jul 1 gang om året 🙂
Hvis man har ændringer i meta title og meta beskrivelse på de forskellige URLs, vil dette tag så stadigvæk have sin effekt, eller skal indholdet være ens?
Hej Tim
Jeg kan ikke finde hoved og hale i dit spørgsmål – beklager. Kan du omformulere det?
Jeg kan dog fortælle dig, at “meta title” er helt og aldeles ligegyldigt. Det er kun selve tag’et “Title”, der tæller, og det er slet ikke en del af meta.
hehe det er også lidt sent at sidde og arbejde med det 🙂 Jeg er nok lidt træt.
Det er selvfølgelig title jeg mener 🙂
Jeg har en masse kategorier på vores webshop, kategorierne har så en masse sorterings muligheder, her har jeg nogen ændring i title og meta description for at undgå at google tolker det som dublicate content. og det virker egentlig fint nok.
Men da mit open source webshop system ikke helt er så fantastisk med dublicate content og der har sneget sig nogen ekstra parametre ind i URL’en som ikke er dækket ind af ændringer i title og description så har jeg forsøgt mig med rel=Canonical på alle URL’erne der kommer ved sortering. De peger så på den oprindelige URL til kategorien. Desværre så steg mit dublicate content fra 14 sider til 291 sider da jeg lavede denne ændring. Mit spørgsmål er vel egentlig om det kan have noget at gøre med om jeg har ændringer i title og meta description i forhold til den oprindelig URL, så google derfor ikke synes at de sorteret sider er nok ens med den oprindelige til at tagget virker. Problemet er de parametre der har sneget sig ind fordi de giver samme title og description som nogen af de sorteret URL’s, men de har også Canonical tag som peger på den oprindelig kategori side.
Det er sku lidt svært at forklare. Håber det hjælp. 🙂
Det hjalp lidt, Tim. Du har misforstået duplicate content: Du kan IKKE undgå det ved at ændre sidetitler og sidebeskrivelser. Duplicate content beregnes på sidernes tekstindhold. Hvis du ikek har andre udveje, kan Canonical URL tag være en løsning til dit system.
Ikke at vi skal starte en diskussion omkring det, men jeg har løst en del af problem ved ændringerne i title og description, men side indholdet er jo også forskelligt når det er sorteret anderledes.
Men ved du om canonical url tag bliver uvirksomt hvis side indholdet og/eller title og description ikke er helt ens til?
Det behøver vi skam heller ikke diskutere, for fakta er, at DC og titles ikke har noget med hinanden at gøre.
Så spørger du: “Men ved du om canonical url tag bliver uvirksomt hvis side indholdet og/eller title og description ikke er helt ens til?”
Jeg ved ikke, om det er mig, der er tungnem, men jeg kan simpelthen ikke gennemskue, hvad du spørger om.
Nej okey, jeg tror vi snakker forbi hinanden. Når jeg siger ens title så mener jeg selvfølge titlen på den sorteret side og title på den oprindelige (usorteret) side. Det samme med DC som du kalder det. Jeg ved godt at de på samme side er 2 forskellige ting og ikke som sådan har noget med hindanden at gøre.
Lad mig prøve med et eksempel.
Siden:
http://www.verdious-wardrobe.dk/shop/21-sommermoden-2010?orderby=price&orderway=desc&p=10
og
http://www.verdious-wardrobe.dk/shop/21-sommermoden-2010?side=1&%3Bvarekat=&orderby=price&orderway=desc&p=10
Har begge
Men er dømt i webmaster tools som ens sider, og de er også helt ens. Siden de peger på, som canonical URL er dog ikke dømt. Den side de peger på har en delvist anderledes title, DC og indhold.
Jamen – med dit canonicale tag på plads, er det jo fløjtende ligegyldigt. Du fortæller jo netop Google, at de “sorterede sider” har en canonical URL. Og dermed er title på de sorterede sider helt uden betydning.
Det var også det jeg troede, men efter at have taget canonical tag i brug steg mit dublicate content i webmaster tools, heriblandt med sider der har/havde fået tagget. Det synes jeg er underligt, så derfor spørger jeg om det faktum at siderne ikke er helt ens kan gøre at canonical tag ikke virker helt som det burde. Og det er jo her de to sider som har tag, og peger på en 3. side der er helt ens.
Det er sku noget rod at forklare, hvis du ikke får fat i den her, så lader vi den ligge 🙂 Så siger jeg bare mange tak for din tid.
Duplicate content i Webmaster Tools? Det kan du da ikke se i Webmaster Tools! Du kan kun se duplikerede sidetitler og sidebeskrivelser – ikke duplicate content. Det har du vist fået helt galt fat i.
Og velbekomme – det var så lidt 🙂
hmm, så er det måske derfor vi ikke helt har snakket om det samme. Hvor kan man så se dublicate content, og kan man overhovedet det?
Jeps – tjek SEO-LEX. Der lærer du det hele og mere til.
Jeg har meget nytte af Canonical url tag, som jeg bruger i stor stil. 🙂
Jeg synes det er gør det meget nemmere at fortælle google hvilken url de skal benytte.
Spændende læsning, og god video.
Hej Thomas!
Jeg er noget forvirret over det jeg lige har læst her på bloggen.
Du skriver:
Hvis det er dig, der ejer svendbent-kaffemaskiner.dk, skal du indsætte tag’et her: i headeren på svendbent-kaffemaskiner.dk/espresso/model12 og svendbent-kaffemaskiner.dk/italienske/model12
Dermed fortæller du Google (og angiveligt også andre søgemaskiner), at det er svendbent-kaffemaskiner.dk/saeco/model12, der er moderen og den side, de skal prioritere.
Mit spørgsmål:
Er canonical tag’et udelukkende for at få Googles søgemaskiner til at holde focus på “modersiden” eller for man også lidt mere ud af ulejligheden f.eks. at siderne som har canonical tag’et også selvstændig bliver indexeret, rank’et og vist i Googles søgeresultater ?
Som udgangspunkt er tag’et til for at undgå problemer med duplicate content ved at fortælle søgemaskinerne, hvilken af de mulige URLs, der er den kanoniske. En URL med tag’et på kan sagtens indekseres og også ranke, hvis Google finder det betimeligt – men som regel er det nu den kanoniske URL, der vises i SERP. Og indgånede links til de ikke-kanoniske videreføres værdimæssigt til den kanoniske URL.
Opklarede det sagen?
Jeg bemærkede lige at qoute tegnene er forkerte, det er ikke et almindeligt “, men ″ altså skævt (Det sker vidst typisk hvis man skriver i word og bagefter kopiere over i WordPress). Det har ret afgørende betydning hvis man skulle finde på at copy / paste koden ind på sin hjemmeside 🙂
Hej Thomas
Jeg har et spørgsmål vedrørende DC i forhold til index.html.
Når jeg tester/optimerer mit website i programmet “WebMeUp” får jeg negativ respons på DC i forhold til:
dit-domain.dk
dit-domain.dk/index.html
*I menuen skriver jeg kun “index.html – ikke hele url – hvis det nu gør en forskel.
Vad gør man i dette tilfælde?
Mvh Lars
Hej Lars
Jeg kender ikke WebMeUp udover af navn. Faktisk er lidt i tvivl om, hvad du spørger om, men lad mig forsøge:
Hvis din forside svarer med både rod og /index.html, har du et problem med muligt DC og tab af linkjuice. Du skal sikre, at /index.html rewrites til roden, og at alle dine interne links peger på roden og ikke på /index.html
Hej Thomas
Tak for dit hurtige svar.
Jo, du forstår mig ret, undskyld min dårlige forklaring, prøvede enlig bare at gøre problemstillingen lidt kort, men du fangede den 🙂
Tak for hjælpen!
Mvh Lars